I was getting sick of receiving political flyers in the mail, but wanted to know how bad it was. So I saved all flyers I received from 10/1/22 - 11/4/22* and segmented by party and whether it was positive (solely about what the candidate had to offer) or negative (containing elements about how the other candidate will destroy America and/or democracy if they so much as sniff office).
That’s 63 ads just to me. Technically 64, but I’m excluding the sole flyer from the Libertarians I received. Democratic mailings were slightly more likely to be positive, but not by much. Just to see if this matters, we can run a chi-squared test to see if the difference is statistically significant.
Show the code
chisq.test(ads)
Pearson's Chi-squared test with Yates' continuity correction
data: ads
X-squared = 5.3248e-31, df = 1, p-value = 1
If there was a major difference, we’d see a p-value around 0.05. Seeing a 1 mean that, basically, we take a look at our null hypothesis - that there is no difference is the rate of positive ads between the two parties - and say “there is zero reason to say this isn’t true”. We can be a bit more technical with the small sample size and run Fisher’s exact test instead.
Show the code
fisher.test(ads)
Fisher's Exact Test for Count Data
data: ads
p-value = 1
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.3471225 3.4243229
sample estimates:
odds ratio
1.093443
Well, that didn’t move the needle much. We can also run a permutation test, since beating a dead horse can occasional be cathartic.
Show the code
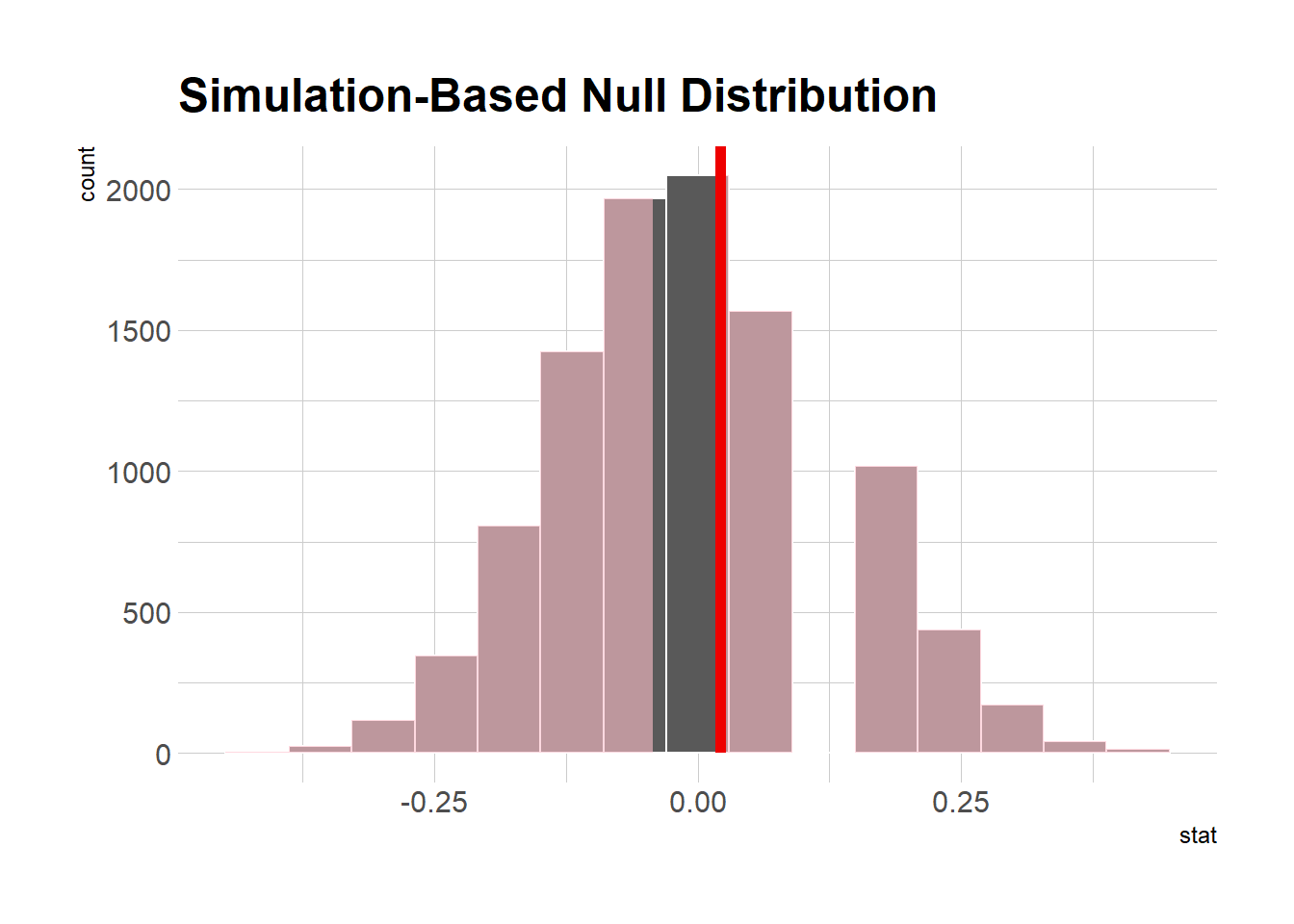
ads_long <- ads %>%as_tibble() %>%uncount(n) %>%mutate(is_positive =case_when(type =='pos'~1, TRUE~0))ads_pos_dif <- ads_long %>%specify(is_positive ~ party) %>%calculate("diff in means", order =c("D", "R"))ads_null_dist <- ads_long %>%specify(is_positive ~ party) %>%hypothesize(null ="independence") %>%generate(reps =10000, type ="permute") %>%calculate("diff in means", order =c("D", "R"))ads_null_dist %>%visualize()+shade_p_value(obs_stat = ads_pos_dif, direction ="two_sided")+theme_ipsum()
Essentially, we observed a 4 point difference in percent positive ads, but when we simulated what we would expect assuming no difference, we expect a range of about +/- 25 points. Since this range contains zero, we can’t say we’ve detected a difference.
This is an important lesson to all aspiring data analysts - you won’t always find a statistically significant result in your data, tutorials notwithstanding. In this case, it suggests that both parties act similarly, at least based on this sample.
The other lesson is that yes, there are 63 flyers in play here, but to one household. My demographic information - age, marital status, income, zip code, etc. - may have influenced the types of ads I did and didn’t receive, so my data may have skews I’m unable to observe or control for. While it’s semi-reasonable to assume that these findings would hold true for the broader population, we can’t be super-confident in that assumption. That said, having watched more ads than usual during the World Series lately, this passes the sniff test - both parties are more than happy to go negative, and if one says the other is doing it more they’re not looking at the data.