We’re all familiar with averages. Whether we’re discussing average spend per order or average height, it’s something we use all the time. And with good reason - it’s a great shorthand way to say “this is what we’d typically expect”.
Averages can be tricky things, though. To illustrate this, let’s look at some data on the Boston Marathon from 2015-2017* (available here - Kaggle is the best). Let’s look at the overall average time in minutes in all three years.
*There’s a lot of nuance in the data - we’ll tackle that later, so if you think I missed something, hold tight.
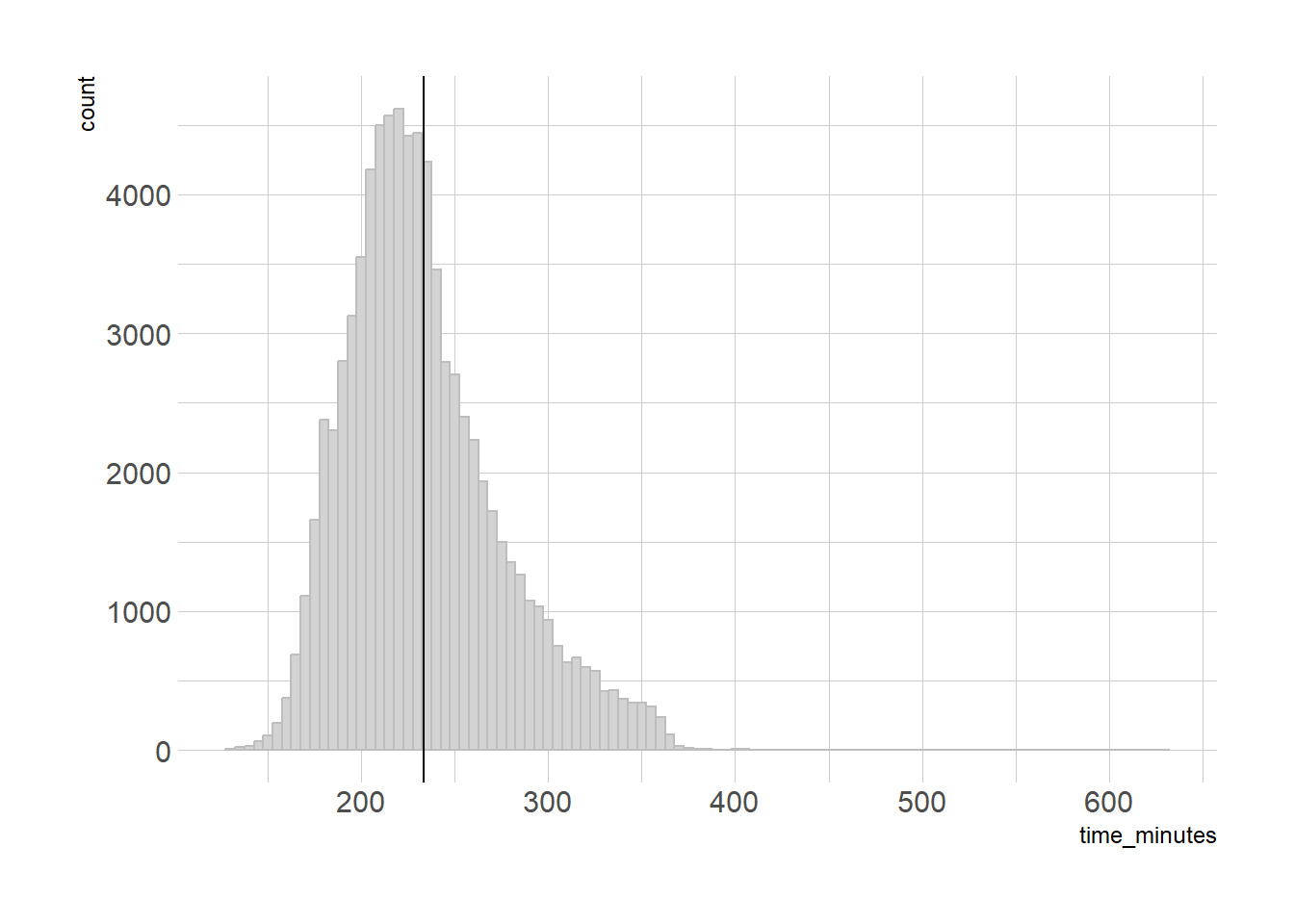
So the average runner finished around 3 hours 53 minutes. Not too shabby, and way ahead of where I’d be. If we put all finish times in 5 minute increments and showed what the average is, it should be right about the center.
Show the code
marathons %>%ggplot(aes(x = time_minutes))+geom_histogram(binwidth =5, color ='grey', fill ='lightgrey')+theme_ipsum()+geom_vline(xintercept = overall_mean)
Well, it’s not bad, but it’s a bit more to the right than we’d like. Our average does a decent job, but it’s being pulled higher by some slower times way on the right. What % is below average?
Show the code
mean(marathons$time_minutes < overall_mean)
[1] 0.5743489
What we have now is a reverse Lake Wobegone situation, where all our runners are below average. 57% below is not quite as descriptive as we were hoping for. Thankfully, we have the median instead. The median is just the number directly in the middle, so 50% will be above and 50% below.
*Unless there’s an even number of runners, in which case we average out the middle two numbers. Our histogram suggests that won’t be a problem with this data, but that may not hold true for all data sets.
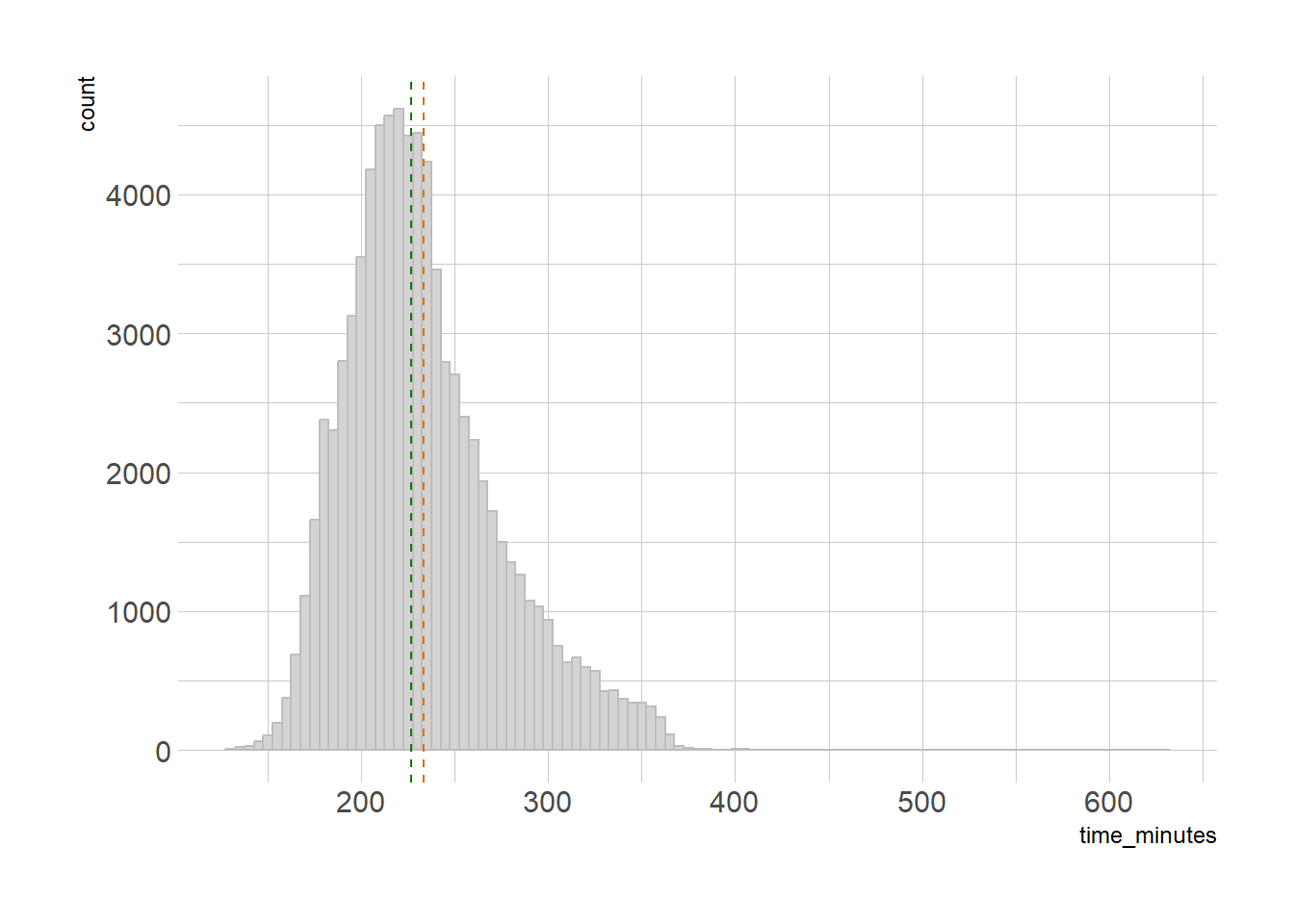
Our median is 226 minutes, compared to our mean of 233. That’s 7 minutes, which for many runners here ample time to run a full mile, so this not a trivial difference. Let’s plot this again, this time showing the mean in orange and the median in green.
Show the code
marathons %>%ggplot(aes(x = time_minutes))+geom_histogram(binwidth =5, color ='grey', fill ='lightgrey')+theme_ipsum()+geom_vline(xintercept = overall_mean, color ='#e36e07', linetype="dashed")+geom_vline(xintercept = overall_median, color ='#0c7806', linetype="dashed")
This is looking a lot better. This isn’t to say the mean is never appropriate, though - the fact that the mean can be multiplied by the count to get the total can be very meaningful when dealing with dollars, even when the mean isn’t very representative of the data, which is why we should visualize the distribution anyway. If you’re looking for the right answer on which to use when, the answer is going to be “it depends”. It depends on your data and what decisions you need to make from it.
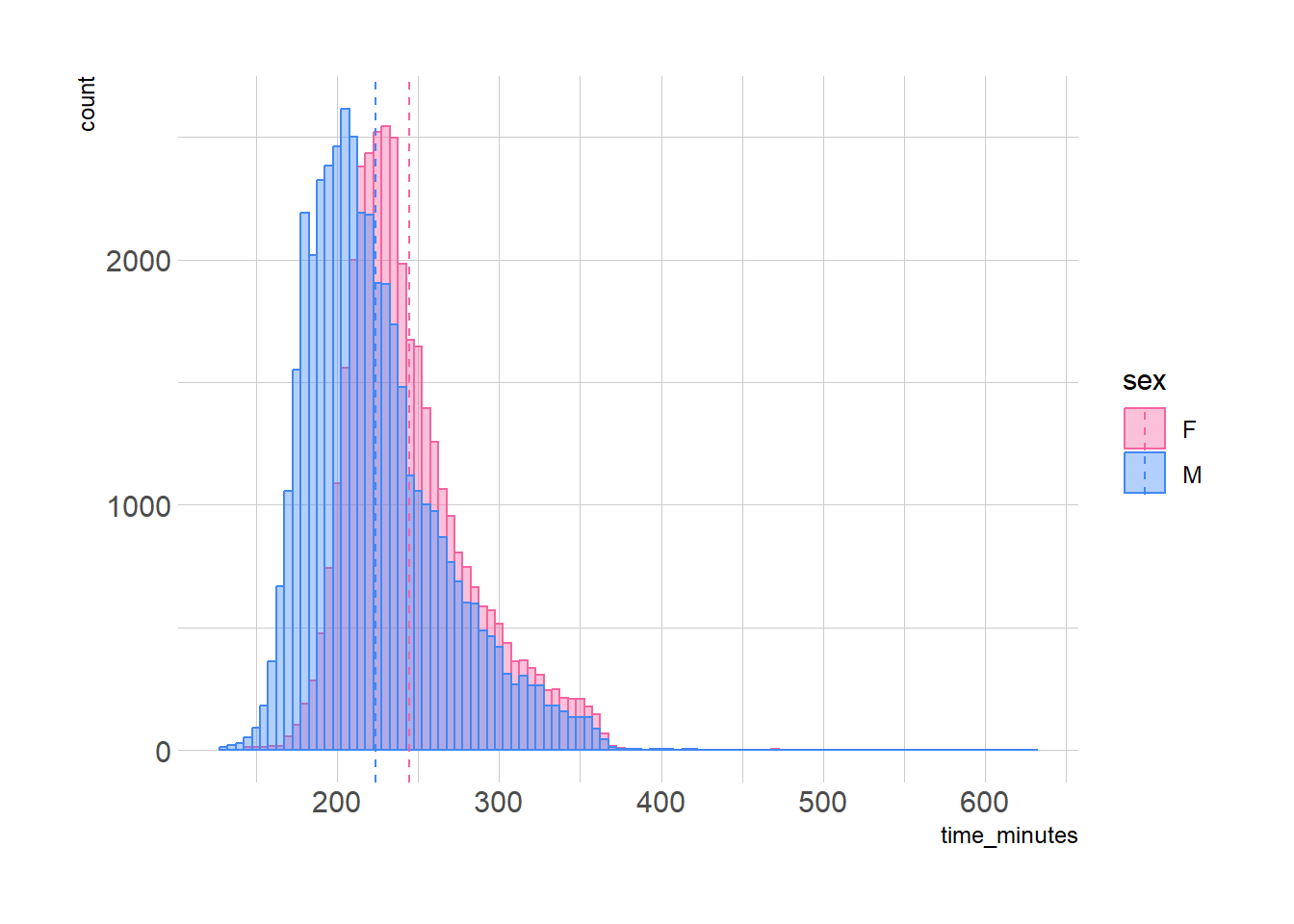
So far, we’ve been looking at a single mean, but the data can have multiple means. For instance, what if we split by sex?
We now have two overlapping distributions, each with its own mean. Men average 224 minutes, women 244. But that doesn’t mean that all women are slower than all men, we can clearly see there’s a significant overlap. There are tests we can run to see if the 20 second difference is something we’d consider meaningful, but for now, we’ll note it and move on.
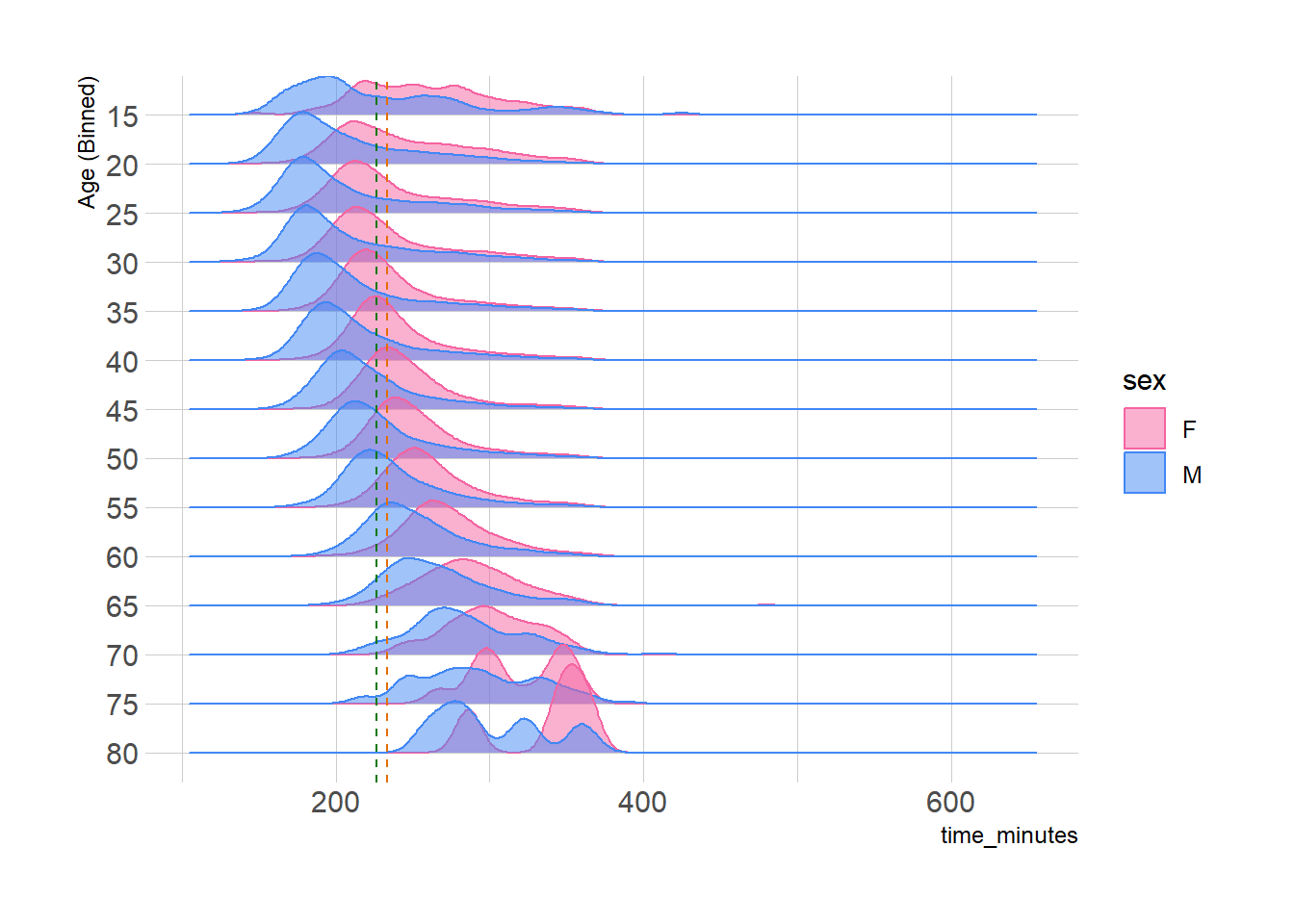
We can also look at this by age. Since we’ve already seen a difference in gender, we’ll keep that as well. Rather than looking at 80 some ages all at once, we’ll group by five year increments - so ages 20-24 will appear in the “20” group, 25-29 in the “25” group, and so on. We’ll also include our earlier mean (orange) and median (green) lines for the overall population to see how well they fit.
Show the code
marathons %>%mutate(age_binned =as.factor(floor(as.integer(Age/5)*5))) %>%ggplot(aes(x = time_minutes, y =reorder(age_binned, desc(age_binned)), color = sex, fill = sex))+geom_density_ridges(alpha =0.5)+theme_ipsum()+scale_colour_manual(values =c("#f564a1", "#4287f5", "grey"))+scale_fill_manual(values =c('#f564a1', '#4287f5', 'grey'))+ylab('Age (Binned)')+geom_vline(xintercept = overall_mean, color ='#e36e07', linetype="dashed")+geom_vline(xintercept = overall_median, color ='#0c7806', linetype="dashed")
The gender difference holds across age, and age is associated with slower times*. Our average lines don’t go a good job with either the younger or older runners, suggesting it’s worth our time to calculate their averages independently. That’s a lot of averages, which we can do pretty easily if we want, but the point we should take is that an average that describes an entire population may not work so well when looking across demographic strata.
*This does look like a lot, but there are many more factors that go into race results, such as height, weight, VO2 max, baseline speed, quality of sleep, diet, etc. We’re only looking at what’s in our data set, not all potential factors.