Measuring Data Spread - Adventures in Standard Deviations
statistics
r
intro to stats
Author
Mark Jurries II
Published
February 6, 2023
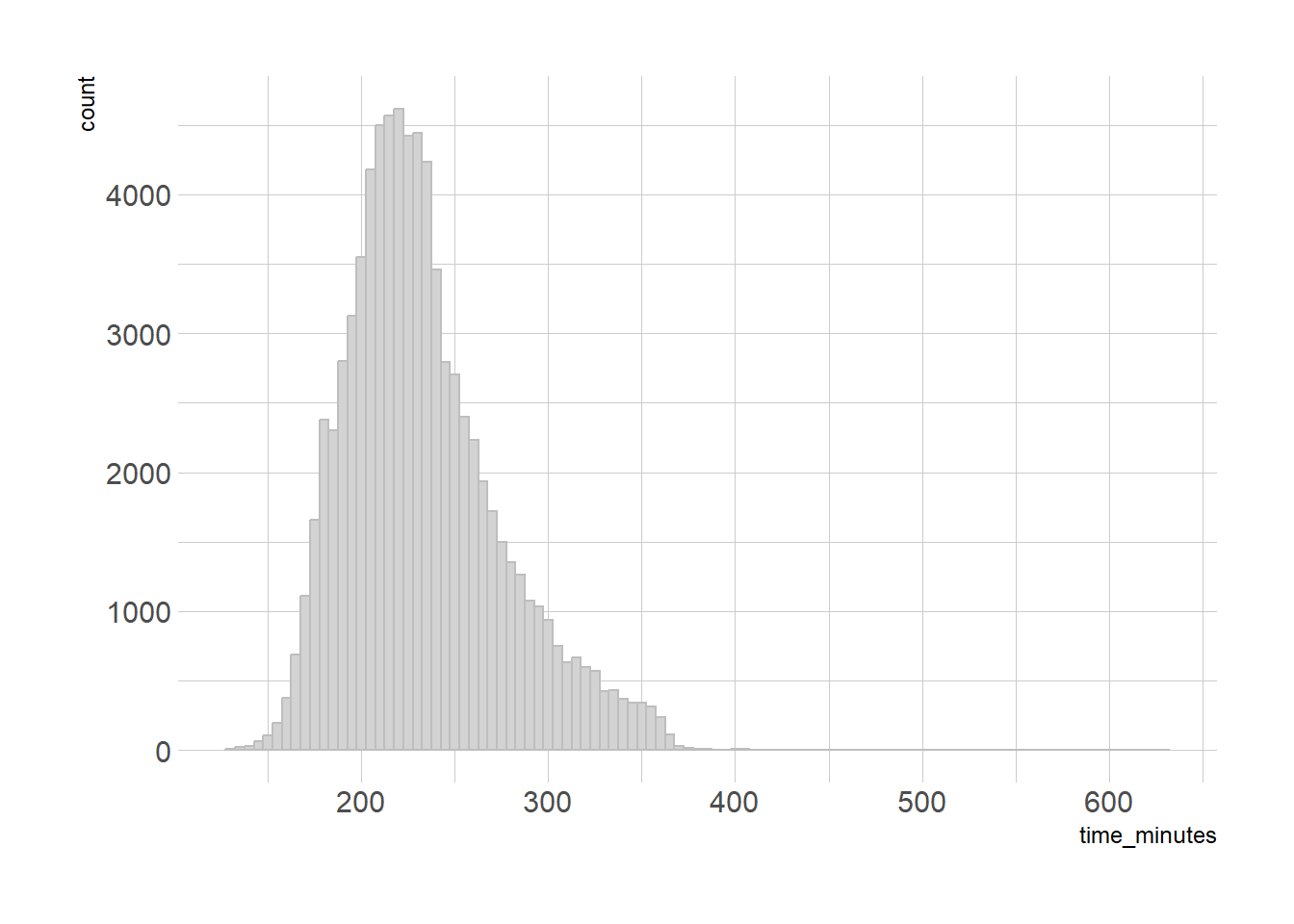
We may know the average (mean or median) of a data set, but we know that there will be points above and below average, and it’s nice to know just how spread out they are. We could just eyeball the distribution, once again using data from the Boston Marathon from 2015-2017* (available here):
This gives us a nice general feel, but it’s hard to eyeball the spread. So let’s start with the most common measure, the standard deviation*. This gives a rough estimate of our far on average numbers are from the mean. We’d expect 95% of values to fall within two standard deviations, that is, between mean - (standard deviation * 2) and mean + (standard deviation * 2).
*This is simply the actual number - the overall average, which we then square to make even. We then average all of these and take the square root to return it to our original scale.
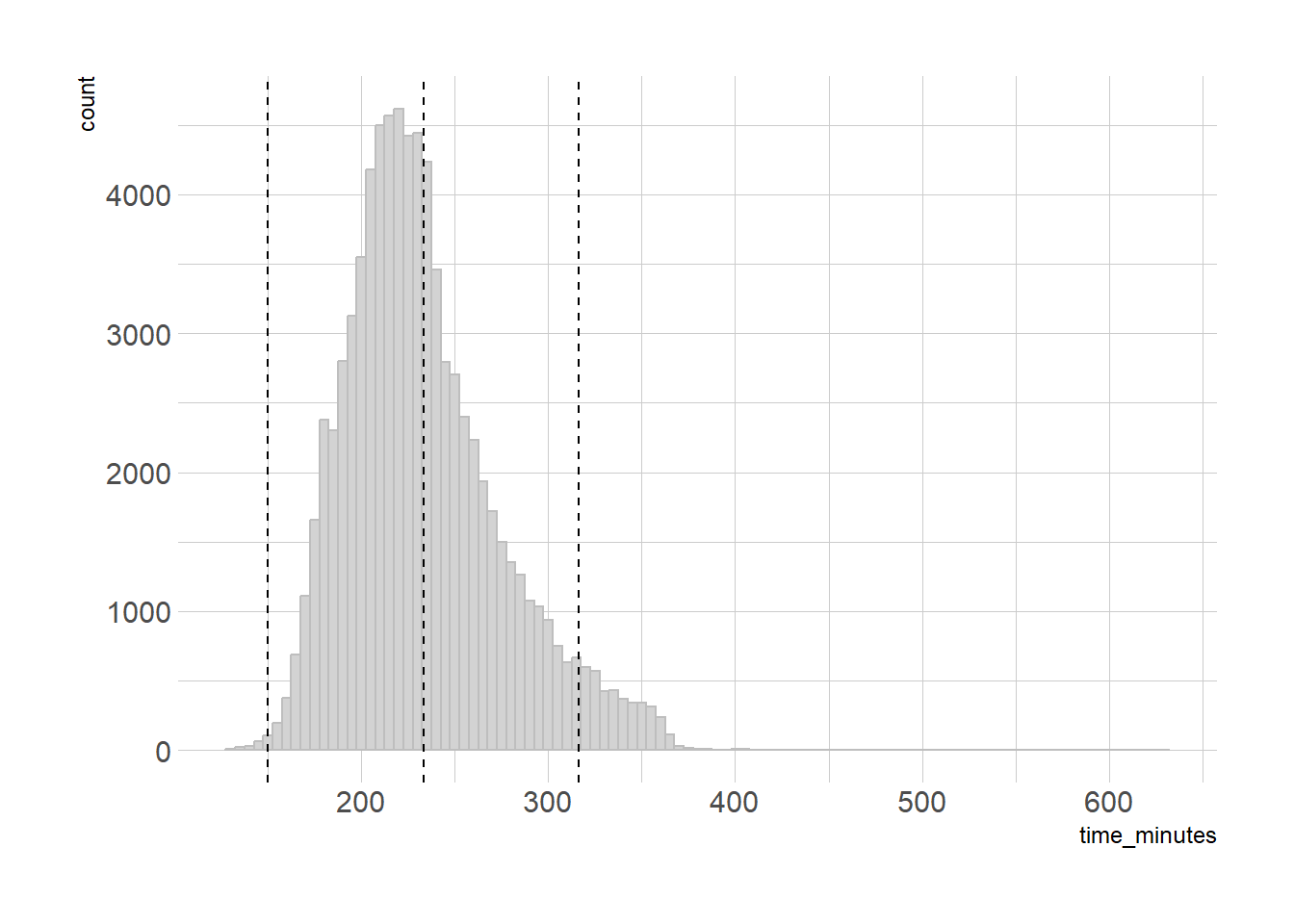
We capture a lot, but many of the slower time on the right are cut off. Our overall average is 233 minutes, with a standard deviation of 41 minutes. So we’d expect 95% of our times to be between 150 and 316 minutes. Our chart suggests that’s not likely, but let’s put it to the test anyway:
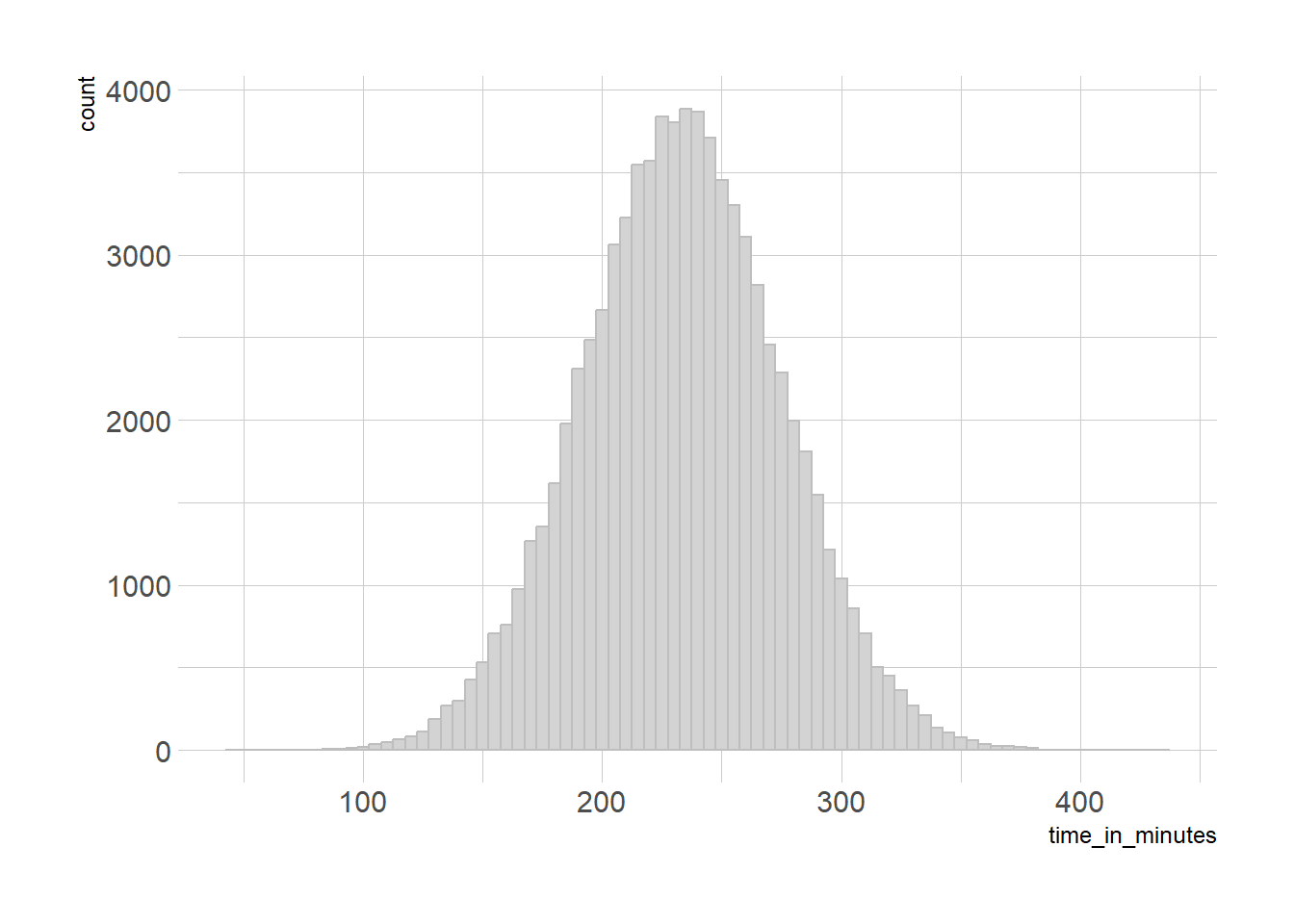
Oof, only 79%? What went wrong? The standard deviation assumes a normal distribution. Our marathon times above have a long right tail, instead of being a nice symmetrical distribution like this:
Show the code
norm_times <-rnorm(79638, overall_mean, overall_sd)norm_times %>%as_tibble() %>%ggplot(aes(x = value))+geom_histogram(binwidth =5, color ='grey', fill ='lightgrey')+theme_ipsum()+xlab('time_in_minutes')
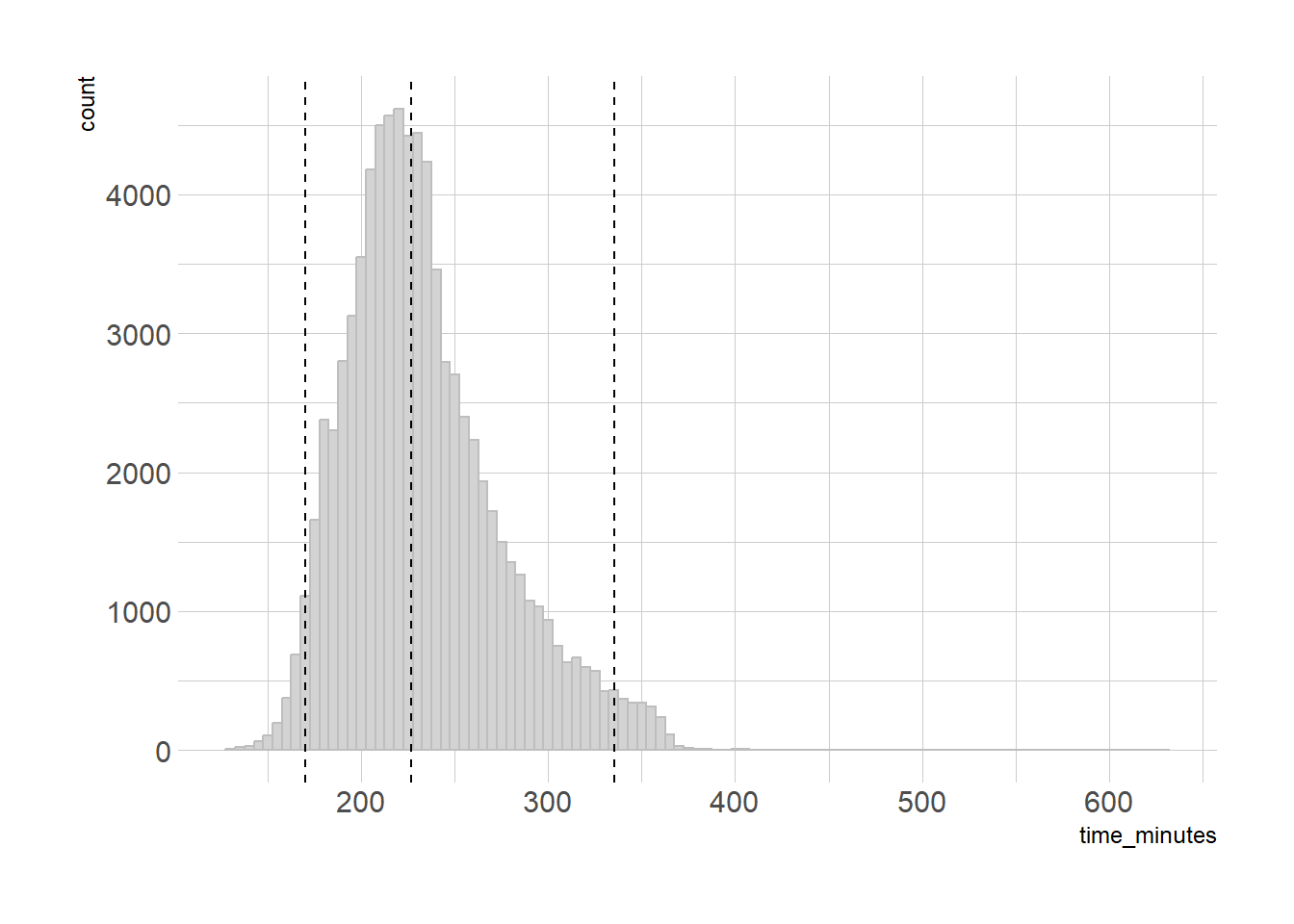
This doesn’t mean that the standard deviation is always bad - there are plenty of times it’s useful, even in some cases where it’s only directionally correct. But many real-world distributions are not normal. Thankfully, we can use percentiles instead. The 2.5% and 97.5% percentiles will contain 95% of the data, and since they’re already percentiles, as an added bonus we don’t have to test.
Another bonus here - the distance from the median to the upper and lower bounds in not the same. The gap from the low to median is 56.6 minutes, while the gap from median to high is 108.8 minutes. So our below-median runners are more compressed, while there’s a wider range above median. You can imagine this would be useful in sales analysis - if you have a bunch of customers placing smaller orders, you may want to run a campaign to increase their basket size.
Another reason for the bunching on the faster side is that there’s a natural floor - there’s only ever been one marathon run under two hours, so we don’t expect to see anything lower than that. Meanwhile, the max could theoretically be anything, though I’m suspicious of the 10.5 hour max in the data. Many real-world datasets have this - for instance, handle time in a call center can never be below 0 seconds, but a handful of hour long calls could skew the average high. Or orders can have a minimum of whatever your lowest priced item is along with an essentially limitless ceiling.
Of course, just like averages, we want to break these down by subgroups to get to the more interesting insights. Let’s show standard deviation and percentiles by sex.
Women have a smaller standard deviation and range than men - it’s 152 minutes from the 2.5% to 97.5% percentiles, while men have 163 minutes. So though men have faster times, they’re less predictable*. So if we were trying to predict finish times, we’d have different ranges for each gender and could adjust based on how wide those ranges are.
*Insert your own joke here.
Ranges may not be as exciting or intuitive as means, but knowing how they work adds an extra level of understanding to the data. This is especially important when testing to see if the means of two groups are different, as a significant amount of overlap will be your first indicator that there may not be anything going on there.